데이터 유형
* 인라이어 데이터
: 예상 값과 실제 올바른 값
* 이상값 데이터
: 이 값은 예상치 못한 값이며 실제로는 잘못되었습니다.

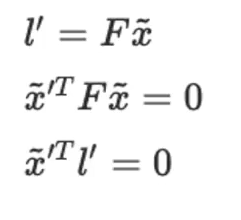
에피폴라 레인은 왼쪽 포인터에 F(기본 행렬)를 곱하여 찾을 수 있습니다.
내부 데이터는 녹색으로, 비정상 데이터는 빨간색으로 표시됩니다.
설명자 일치를 수행할 때 이상치 데이터 픽셀은 일치하는 것으로 평가되지만 움직임 정보를 기반으로 합니다.
기본 행렬에 대한 외삽은 부정확한 값을 초래할 수 있습니다.
이상치 거부
이상치 데이터는 어떻게 생성됩니까?
– 갑작스러운 조명 변경, 회전, 폐색, 모션 블러 및 깨진 형상이 발생할 때 발생합니다.
컴퓨터 비전에는 두 가지 유형의 알고리즘이 있다고 합니다.
– 닫힌 알고리즘
: 정확한 지오메트리가 있을 때 작동하도록 설계된 알고리즘입니다.
-> 예를 들어 : 8점 알고리즘인 경우 일치하지 않는 항목이 있으면 잘못된 결과를 얻게 됩니다.
– 반복 최적화
: 데이터 분포에서 패턴을 찾아 좋은 결과를 내는 알고리즘.
-> 비정상적인 데이터에서 패턴을 찾아 결과를 생성합니다. 데이터가 이 결과를 따르지 않으면 잘못된 패턴을 추론하게 됩니다.
따라서 알고리즘을 실행하기 전에 이상값 데이터 제거중요한
모델 피팅
-> 이상치 거부 필요
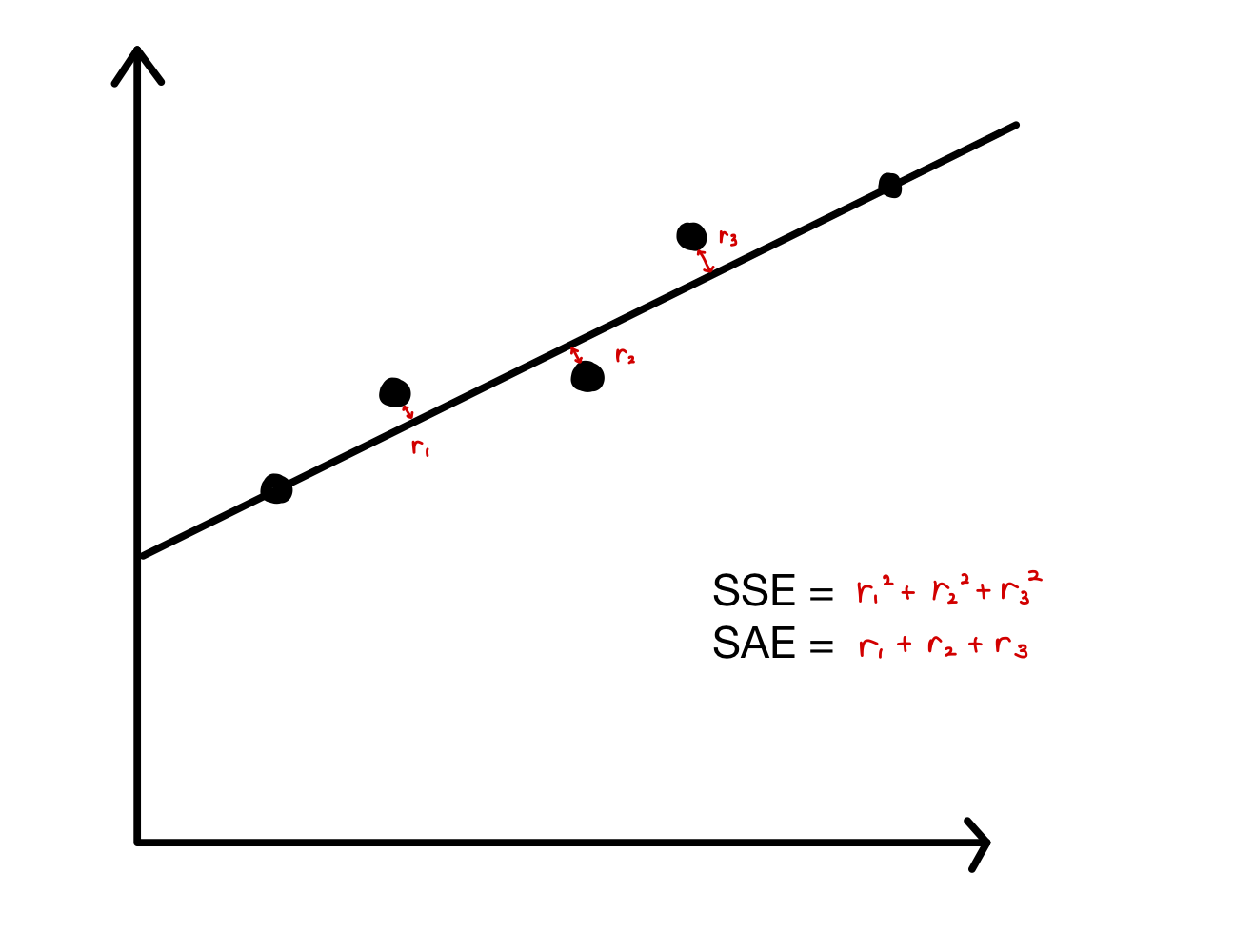
SSE 또는 SAE 값의 평균 또는 합계가 가장 작은 선이 가장 정확합니다.
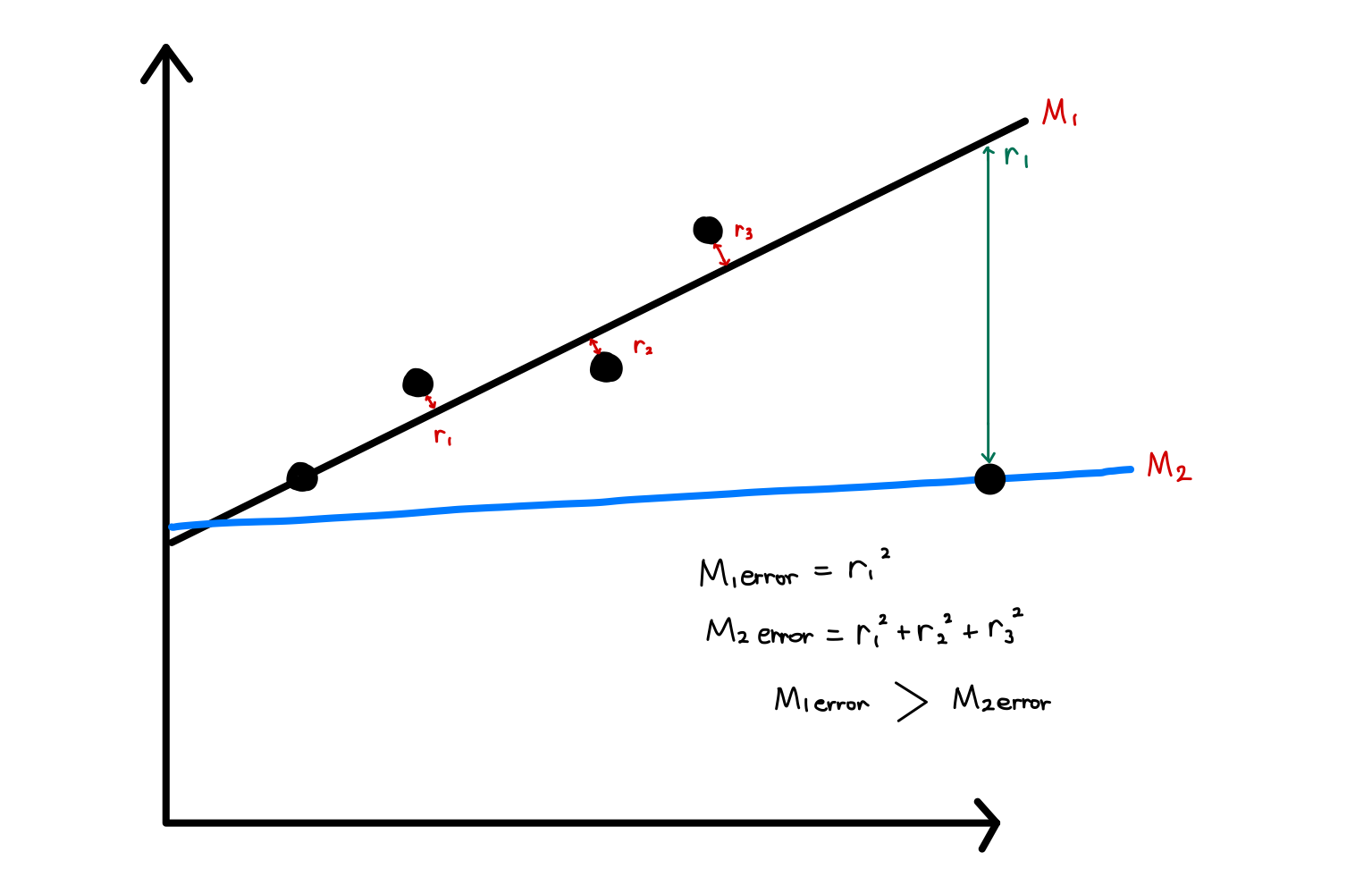
대다수의 사람들이 좋은 모델을 가지고 있더라도 이상치 때문에 나쁜 모델을 추론할 수 있습니다.
RANSAC (: 랜덤 샘플링 컨센서스)
-> “임의의 데이터 샘플을 취하여 모델을 만들고 데이터가 모델에 얼마나 잘 맞는지 알아보십시오.”
작동 방식
1. 최소 데이터 집합을 임의로 선택합니다.
(예: 8포인트 산술에는 8이 필요함)
2. 샘플 데이터에서 모델을 추론합니다.
3. 모델 점수를 평가합니다. 현재 점수가 이전 최고 점수보다 높으면 업데이트됩니다.
4. 1단계로 돌아갑니다.
작동 방식의 예(Homography에서 RANSAC를 실행하는 예)
1. 많은 데이터에서 4개의 특징 일치를 선택합니다. (호모그래피를 얻기 위해 필요한 데이터는 4쌍의 특징 일치입니다.)
2. 이 데이터에서 호모그래피 행렬을 추론합니다.
3. 왼쪽 이미지의 픽셀 값에 호모그래피 행렬을 곱합니다. 그런 다음 오른쪽 이미지의 기능에 해당하도록 픽셀을 올려야 하지만 데이터에 노이즈가 있으면 올바르게 표시되지 않습니다. 이 모든 픽셀 거리를 측정하고 더할 것입니다. 이를 재투영 오류라고 합니다.
또는 오류 임계값을 설정하여 2픽셀 이상 떨어져 있는 항목만 재투영 오류로 판단합니다.
따라서 최신 점수가 이전 최고 점수보다 높으면 업데이트됩니다.
4. 1단계로 돌아갑니다.
이 루프는 얼마나 오래 실행되어야 합니까?
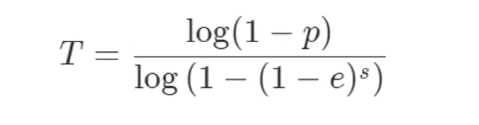
T: 최적의 모델을 얻기 위해 실행할 루프 수
P: 선택한 모든 모델이 inlier 데이터를 포함해야 할 확률
e: 전체 데이터에서 인라이어와 아웃라이어의 비율
s : 루프당 샘플링할 샘플 수
예)
99%의 정확도를 원한다면 p=0.99
특이치 대 이상치의 비율은 50% e=0.5입니다.
s는 알고리즘마다 다름(P3P: 3, Homography: 4, Fundamental Matrix: 5, Fundamental Matrix: 8)
호모그래피를 사용하는 경우 s = 4
그러면 T를 얻을 수 있습니다.
RANSAC 장단점
이점
- RANSAC가 성공하면 inlier만 있는 모델을 추론한 다음 데이터 세트에서 이상값을 성공적으로 제거할 수 있습니다.
- 데이터 분포를 분석하지 않고도 이 작업을 수행할 수 있습니다.
- 전체 프로세스 시간은 다소 예측 가능합니다.
- 이해하기 쉽습니다.
피해
- 돌릴 때마다 결과가 달라집니다. (동일한 데이터라도 성공할 때도 있고 실패할 때도 있다.)
- 전체 데이터셋에서 inliers보다 outliers가 더 많으면 실행 시간이 길어집니다.
- 그것이 실패하면 모든 가능성을 찾는 것으로 수렴된다.
- 데이터 세트에서 여러 모델을 추출할 수 없습니다.
모던 랜삭
기존의 RANSAC은 데이터의 분포와 선행 데이터를 알고 있어도 단순히 활용할 수 없는 알고리즘입니다.
그러나 하나의 데이터 세트에서 여러 모델을 추출할 수 없는 문제는 여전히 불가능합니다.
몇 가지 수정된 RANSAC가 있습니다.
-MSAC, MLESAC, Lo-RANSAC, NAPSAC, P-NAPSAC, DEGENSAC, PROSAC, MAGSAC, APRANSAC
향상된 RANSAC은 OpenCV 4.5 이상부터 사용할 수 있다고 합니다.
이것은 교사가 E와 F 값을 얻을 때 자주 사용하는 조합입니다.
– 조기 정지
– 프로삭
-Lo-RANSAC
1. 조기 정지
RANSAC이 좋은 모델을 빨리 찾을 수 있을 만큼 운이 좋다면 즉시 RANSAC을 종료하는 것은 어떻습니까?
CPU 주기가 비게 될 때마다 다른 CPU 코어에서 CPU 주기를 가져오거나 신속하게 다음 프로세스를 불러와 실행할 수 있는 방법이 있습니다.
이 방법을 구현하려면 세 가지 변수를 미리 정의해야 합니다. 1. 보장된 최소 품질 RANSAC 주기 2. 최대 주기 수 제한 3. RANSAC에서 추론한 모델이 성공 지표를 초과하면 즉시 종료합니다.
2. 프로삭
: RANSAC 기술은 이미지 매칭을 위해 특별히 사용되며 알고리즘은 사전에 데이터를 잘 활용합니다.
전제
- descriptor matching을 수행할 때 L2norm 또는 Hamming Distance를 측정하는데 이러한 feature descriptor 간의 거리가 작을수록 모델을 추론할 때 inlier가 커진다.
- 우리는 RANSAC의 무작위 샘플링 프로세스를 더 낮은 거리에서 샘플 디스크립터 일치를 기술로 대체합니다.
진행 방법
1. 두 개의 이미지에 대해 디스크립터 매칭을 수행합니다. (이 과정에서 모든 게임이 녹화됩니다.)
2. 이러한 일치 항목을 포함하는 벡터가 있는 경우 오름차순으로 정렬합니다.
3. PROSAC에서 검색할 풀 크기를 지정합니다.
4. 그런 다음 RANSAC 프로세스를 실행합니다.
1. 데이터는 n개의 검색 풀에서 샘플링됩니다.
2. 데이터를 사용하여 모델을 추론하고 평가합니다.
3. 점수가 높으면 업데이트하고 점수가 낮으면 풀 크기를 늘립니다.
4. RANSAC 주기를 반복합니다.
3. Lo-RANSAC
: 조밀한 내부 점의 특징을 잘 활용한 알고리즘
-> Inlier 데이터를 사용하여 모델을 찾으면 근처에 있으므로 임의의 위치로 이동할 필요가 없습니다.
그래서 Lo-RANSAC은 루프를 돌면서 또 다른 작은 내부 RANSAC을 루프 안에 만들어서 좀 더 정확한 값을 얻으려고 합니다.
진행 방법
1. 최소 데이터 집합을 샘플링합니다.
2. 샘플링된 데이터에서 모델을 추론합니다.
*기존 최고점수가 좋으면 1단계로 넘어갑니다. 새 모델을 선호하는 경우 Inner-RANSAC를 실행하십시오.
1. 새로운 RANSAC을 시작하고, inlier로 판단된 데이터를 새로운 데이터셋으로 취급합니다. (Inlier 데이터를 사용하여 RANSAC을 수행하므로 정확도가 향상됩니다.)
2. 이 샘플 데이터에서 모델을 추론하고 평가합니다.
* 현재 점수가 기존 최고 점수보다 높으면 업데이트하고, 낮으면 2-1단계로 이동합니다.
* 사이클 수가 최대 사이클 수에 도달하면 3단계로 이동합니다.
3. 최적화 방법(예: Gauss-Newton 방법 및 Levenberg-Marquardt 방법)을 사용하면 정답에 더 가까워집니다.
4. 1단계로 이동합니다.